Implementing your own lock-free data structures using standard C++ isn’t something you should attempt unless you really, really know what you are doing (this article summarises why). But you can never become an expert in something if you don’t try, so I went in and did it anyway. Among the stumbling blocks I found there was one that I found particularly surprising, so I decided to write a blog post about it: what happens if your lock-free data structure relies on DWCAS.
DWCAS (Double-width compare-and-swap) is a CPU instruction performing an atomic compare-and-swap operation on a memory location that’s double the native word size. In other words, it gives you 128-bit atomic lock-free variables on a 64-bit CPU. It is available on every x86-64 chip (
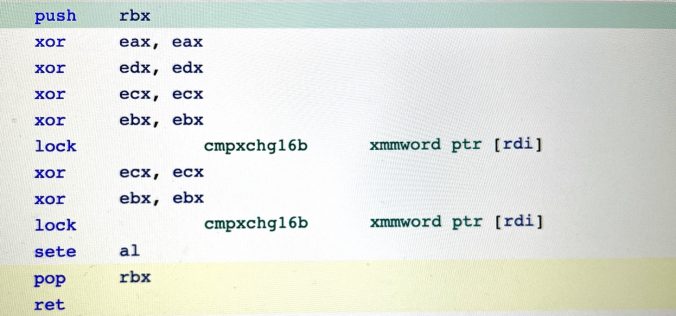
test cmpxchg16b in x86 assembly) apart from some early AMD and Intel Core 2 chips (we’re talking 2008 and earlier). In fact, 64-bit Windows 8.1 and newer requires DWCAS to run.The equivalent DWCAS instruction on a 32-bit Intel chip is
test cmpxchg8b , giving you 64-bit atomic lock-free variables. And on ARM, DWCAS functionality is provided via double-width LL/SC instructions, which seem to be available on all modern ARM chips (32 and 64 bit).With DWCAS, you can implement certain lock-free data structures that would be unimplementable otherwise. I’m not going to go into details about specific data structures here, as this is not the purpose of this blog post (for an example, see here). But given a
struct that contains two pointers, or perhaps, a pointer and an index, such astemplate <typename T>
struct stack_head
{
std::uintptr_t aba_counter;
stack_node<T>* node;
};on a platform that supports DWCAS, I would expect that a
static_assert such as this should succeed:static_assert(std::atomic<stack_head<T>>::is_always_lock_free);and that in a code snippet like this:
head_t next;
head_t orig = head.load();
do
{
node->next = orig.node;
next.aba_counter = orig.aba_counter + 1;
next.node = node;
}
while (!head.compare_exchange_weak(orig, next));the compare_exchange_weak should compile to test cmpxchg16b on x86_64 (and the equivalent instructions on other architectures). In other words, I would expect a guarantee that the compiler will not insert any mutexes into the std::atomic and the code will be lock-free and race-free with the best performance possible.
As it turns out, I was a bit over-optimistic here. When compiling for 32-bit x86, everything is great: the
static_assert succeeds and the test cmpxchg8b instruction gets generated on all major C++ compilers (godbolt). On some compilers, this only happens if you align the struct to 8 bytes using alignas, but that is easily done. However, on x86_64, a much more important platform these days, things look less rosy.The only compiler I could find on which the
static_assert passes and the correct instructions are generated out of the box when targeting 64 bit is the current Apple Clang. This works when compiling for Apple Silicon as well as when compiling for Intel, all the way down to deployment target macOS 10.7 (this is the oldest that my version of Clang supports). I suppose this is because Apple knows exactly what CPUs their OS can run on, and have a modified backend in their Clang fork that uses DWCAS whenever possible. So if Apple is the only platform you’re interested in, then we’re good. Which of course isn’t helpful at all if your goal is a portable, generic C++ library.When using non-Apple Clang (version 13) on x86_64 Linux, the
static_assert fails, and the compiler will instead generate a library call to __atomic_compare_exchange , which may insert mutexes (see documentation here).My guess is that Linux wants to keep supporting those old CPUs, sacrificing the ability to use DWCAS in the process. And unfortunately DWCAS availability is a property of the machine the code runs on, not the machine that’s compiling the code, so there is no way to check for it at compile time.
On Linux, you can check for DWCAS availability at runtime (if you open
/proc/cpuinfo, it will be listed as cx16). So presumably they could do at least a runtime check here, and give us a runtime guarantee that those library calls will use DWCAS instead of mutexes if the CPU supports it. But that’s not what’s happening: if you call the node.is_lock_free() member function on a std::atomic<stack_node<T>> object (which, unlike is_always_lock_free, is a per-instance runtime check), it still returns false on my brand new Linux machine with an 11th Generation (Tiger Lake) Intel Core i9 CPU.It seems that there might be a way around this: passing the compiler flag
-mcx16, which assumes DWCAS availability. On Clang, this will do the right thing, if and only if you overalign the struct to 16 bytes (godbolt). If you then run the binary on an old CPU without DWCAS, it will presumably just crash. Which is fine if we don’t care about those.However, this still isn’t a solution, because then you’d need to compile your whole program with
-mcx16. If you don’t (or if you can’t, because you’re shipping a library), you will get ODR violations and undefined behaviour because now there are two diverging definitions of std::atomic floating around in your binary. And I haven’t found a way yet to programmatically check whether the -mcx16 flag was set, so you can’t even warn your users about this. Which leaves us with the conclusion that you cannot ship a C++ library relying on DWCAS availability on Clang.On GCC, things look even more dire. Here, even the
-mcx16 flag does not help: regardless of what you do, GCC simply won’t emit DWCAS instructions on x86_64. Instead, it will always issue calls into libatomic, and either report that is_lock_free() == false , or (on my machine) not link at all because the default libatomic contains no implementation of std::atomic for double-width underlying types.The fact that GCC fails to emit DWCAS instructions even with
-mcx16 has resulted in several bug reports (here, here, and here), but apparently GCC folks have decided that this is by design and won’t be fixed. Which means: no lock-free DWCAS on Linux.And with this, we finally come to Windows. Remember that , if your machine can run 64-bit Windows 8.1 and newer, it definitely has native DWCAS available. Hilariously, MSVC still reports
is_lock_free() == false, and emits mutexes instead of DWCAS instructions.The only explanation I could find is that fixing
std::atomic would constitute an ABI break, so they won’t do that. It’s another sad example of choosing ABI stability over performance, which continues to baffle me, given that C++’s tag line is to give the programmer the tools for best performance and “leave no room for a lower-level language”.If you still want DWCAS on Windows, Microsoft tells you to use the
InterlockedCompareExchange128 function from winnt.h (docs here). So if you want portable code, you basically have to implement your own std::atomic and use that under the hood. This is the case for both x86_64 and ARM.Looking at ARM across compilers, we get a similar mixed bag like on x86. We already said that Apple Clang works, while MSVC doesn’t. Looking at non-Apple Clang and GCC, it turns out that on armv7 (32-bit), GCC says it’s lock-free and emits the correct double-width LL/SC instructions, while Clang does not (godbolt). On arm64, it’s the other way around: Clang says it’s lock-free and emits the correct instructions, while GCC does not (godbolt).
My conclusion from all this: if you want to have a
std::atomic that portably uses DWCAS instead of silently adding locks into your code (and I don’t think anyone would want that?), your only option is to implement your own std::atomic for all relevant target platforms, or to use a third-party library that does it for you. Which is a really sad state of affairs: I am currently not aware of a free and open source implementation that works on all major compilers and operating systems. If somebody knows such a library, please let me know!In the absence of a free and open source third-party solution, I might attempt to implement and release my own version as soon as I can find the time for it. Windows seems easy, and macOS is trivial, but making it work on Linux could amount to a massive amount of work (basically, reimplementing parts of libatomic, which isn’t exactly approachable, straightforward, or within my area of expertise). Given all the other projects I have going on at the moment, it might take a while before I get to it…
“On Clang, this will do the right thing, if and only if you over-align the struct to 16 bytes ”
Looking at the Intel X86_64 architecture manual (link below), we find “Note that CMPXCHG16B requires that the destination (memory) operand be 16-byte aligned. “, so this is not over-alignment, but what is required by the hardware. Therefore if the compiler used cmpxchg16b on less aligned addresses it would be doing the wrong thing.
Such a requirement is unsurprising if you consider the implementation issues; the implementation wants to load a single cache-line in exclusive more, hold it in a non-snoopable state for the execution of the instruction, and then release it. If the alignment is is only 8B, then the 16B item being operated on could cross a cache-line boundary, so you’d need to hold two lines, which introduces a lot of “fun” in the implementation.
Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 2A: Instruction Set Reference, A-L: https://cdrdv2.intel.com/v1/dl/getContent/671199
That all sounds correct. What I meant by “over-alignment” is that you need to align the type to an alignment that is stricter (= greater) than the alignment requirement of the type in question according to the C++ type system:
https://eel.is/c++draft/basic.align#1
At least on some platforms, the C++ alignment requirement would be 8 bytes instead of the 16 bytes required by CMPXCHG16B. So when I say “over-align” I mean: you need to add an `alignas` specifier to get the required 16 bytes alignment.
“If somebody knows such a library, please let me know!”
Boost uses dwcas by default on all the platforms that support it (and even on some platforms that do not support it, so you have to disable it manually via BOOST_ATOMIC_NO_CMPXCHG16B).
Source code of the library https://github.com/boostorg/atomic
Thanks, Antony! This is super useful to know!
I just had a look, and indeed, they implement the whole thing by hand! For example, x86 128-bit CAS for GCC is implemented here: https://github.com/boostorg/atomic/blob/f72bef98e0117fb2952235ae86bbc29ce8c50454/include/boost/atomic/detail/core_arch_ops_gcc_x86.hpp#L932