In 2019, I had a very busy conference year. I had just become self-employed, which meant I did not have to ask anyone’s permission anymore to go to a C++ conference. And because conferences are fun, I decided to go to all of them. Well, not all of them, but I ended up speaking at quite a few that year: CppOnSea (Folkestone), ACCU (Bristol), using std::cpp (Madrid), 4Developers (Warsaw), C++Now (Aspen), CoreC++ (Tel Aviv), C++Russia (both of them – Moscow & St. Petersburg), CppCon (Denver), ACCU Autumn (Belfast), MeetingC++ (Berlin), and finally CoreHard (Minsk). The latter one was particularly memorable because it was the first time a C++ conference invited me to deliver the opening keynote (and it was an amazing experience – thank you!).
All of these events were amazing in their own way, but I think I overdid it a little bit. So for 2020, I decided to do fewer conferences and try to get some actual work done. I succeeded, but not in the way I expected – as the Covid-19 pandemic hit the C++ community, all events that would normally be in my calendar got cancelled or postponed.
In February 2020, at the C++ committee meeting in Prague, we finished C++20. The international travel bans and conference cancellations started just a few weeks after that. So these days I hear from many fellow committee members how disappointed they are that we finished C++20 but they didn’t get to tell anyone about it afterwards – or at least, not in front of a live audience. I consider myself very fortunate: I am one of probably very few people who managed to sneak in such a C++20 talk just after Prague – and just before Covid-19 hit us. It was the opening talk for C++ Siberia 2020, and since it was such an amazing event and such a memorable trip overall (and my last trip before I started self-isolating), I decided to write up a trip report here.
Continue reading
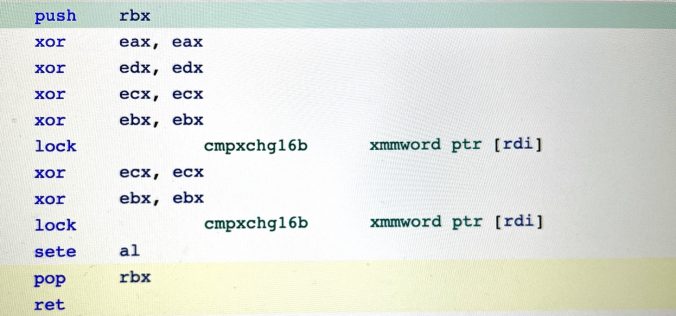


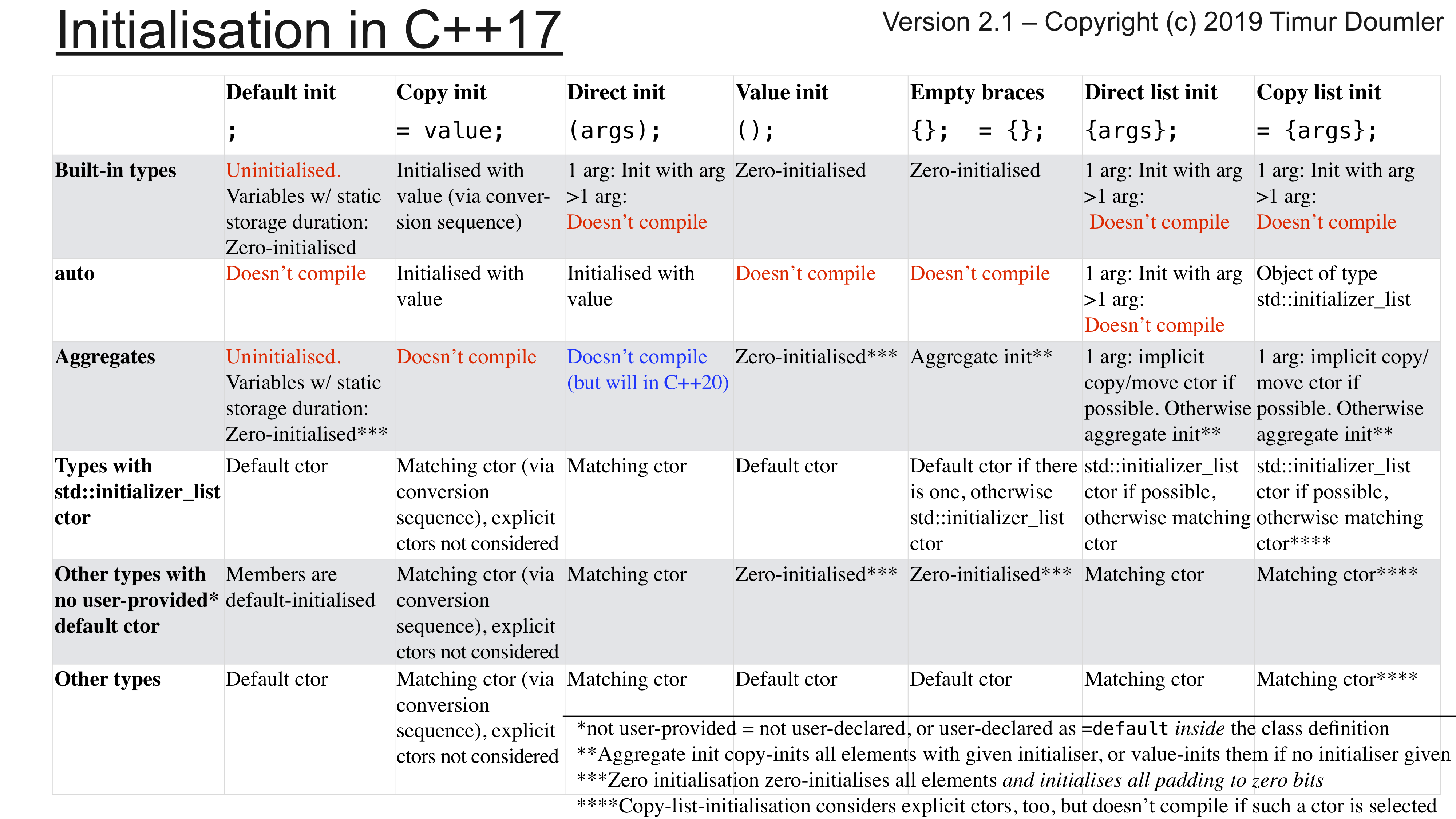

Recent Comments