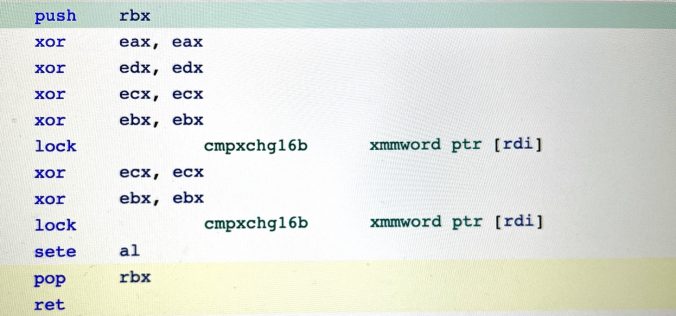
Implementing your own lock-free data structures using standard C++ isn’t something you should attempt unless you really, really know what you are doing (this article summarises why). But you can never become an expert in something if you don’t try, so I went in and did it anyway. Among the stumbling blocks I found there was one that I found particularly surprising, so I decided to write a blog post about it: what happens if your lock-free data structure relies on DWCAS.
Category: C++

Trip report: C++ Siberia 2020
In 2019, I had a very busy conference year. I had just become self-employed, which meant I did not have to ask anyone’s permission anymore to go to a C++ conference. And because conferences are fun, I decided to go to all of them. Well, not all of them, but I ended up speaking at quite a few that year: CppOnSea (Folkestone), ACCU (Bristol), using std::cpp (Madrid), 4Developers (Warsaw), C++Now (Aspen), CoreC++ (Tel Aviv), C++Russia (both of them – Moscow & St. Petersburg), CppCon (Denver), ACCU Autumn (Belfast), MeetingC++ (Berlin), and finally CoreHard (Minsk). The latter one was particularly memorable because it was the first time a C++ conference invited me to deliver the opening keynote (and it was an amazing experience – thank you!).
All of these events were amazing in their own way, but I think I overdid it a little bit. So for 2020, I decided to do fewer conferences and try to get some actual work done. I succeeded, but not in the way I expected – as the Covid-19 pandemic hit the C++ community, all events that would normally be in my calendar got cancelled or postponed.
In February 2020, at the C++ committee meeting in Prague, we finished C++20. The international travel bans and conference cancellations started just a few weeks after that. So these days I hear from many fellow committee members how disappointed they are that we finished C++20 but they didn’t get to tell anyone about it afterwards – or at least, not in front of a live audience. I consider myself very fortunate: I am one of probably very few people who managed to sneak in such a C++20 talk just after Prague – and just before Covid-19 hit us. It was the opening talk for C++ Siberia 2020, and since it was such an amazing event and such a memorable trip overall (and my last trip before I started self-isolating), I decided to write up a trip report here.
Continue readingWhen developing music software, you are operating under tight time constraints. The time between subsequent audio processing callbacks is typically between 1-10 ms. A common default setting is a buffer size of 128 samples at a sample rate of 44,100 Hz, which translates to 2.9 ms in between callbacks. If your process does not compute its audio output and write it into the provided buffer before this deadline, you will get an audible glitch, rendering your product worthless for professional use.
It is therefore commonly taught that you cannot do anything on the audio thread that might block the thread or otherwise take an unknown amount of time, such as allocating memory, performing any system call, or doing any I/O. This includes waiting on a mutex, which not only blocks the audio thread but also leads to priority inversion. This is well known and covered in many articles and talks, such as Ross Bencina’s seminal article, my own CppCon 2015 talk, and more recently a brilliant series of talks by Dave Rowland and Fabian Renn-Giles (part 1, part 2).
So how do we synchronise the audio thread with the rest of our application?
Continue reading
Trip report: February 2020 ISO C++ committee meeting, Prague
If you’re wondering why I didn’t write up a trip report for the November 2019 Belfast meeting – it’s because I gave that report live on CppCast instead. So check it out if you want to hear what happened at that meeting!
But more recently, last month the C++ committee met in Prague, Czech Republic, for the final meeting of the C++20 release cycle. Which means: C++20 is done!
As usual, if you want to hear a detailed report of what actually happened, I can refer you to the excellent trip reports on reddit and on Herb Sutter’s blog.
I personally believe that C++20 is the most important update of the standard in this language’s history. It will change the way we write code, the way we think about classes and functions, and the way we organise and compile our programs in profound ways.
But there are numerous other talks and articles on C++20 and its great features.
So in this report – even more than I usually do – I’d like to focus instead on the things that I was working on myself during the Prague meeting (even if they are a bit niche compared to the big features). Just in case you’re curious what I’m actually doing on the committee these days!
As a C++ committee member, my biggest problem is that it’s virtually impossible to really understand all the new features that are being added to the language – there are simply too many. The survival strategy is to limit your studies to a subset, at a pace that your brain can handle.
And so I only now finally started getting my head around ranges, even though they are probably the most significant standard library feature coming in C++20.
There’s a lot I like about ranges. Most importantly, they finally make STL algorithms composable. Did you ever have to implement your own transform_if because there was no way to chain std::copy_if and std::transform? Ranges let you do that.
But the learning curve is somewhat steeper than I had hoped.
Continue readingA few weeks ago, the C++ committee descended upon Cologne, Germany, to finalise the C++20 Committee Draft (or in other words, our “release candidate” for C++20).
We will now have two more meetings, in Belfast and Prague, to iron out any last-minute bugs and address national body comments, and to then actually ship the new C++20 standard.
As usual, my trip report does not aim for completeness at all. Instead, it focuses on a few particular areas that I was involved in personally and/or things that might be relevant for the audio community.
Continue readingRecently, I gave a talk titled “Initialisation in modern C++”, which was apparently quite well received. (A video recording is available here).
One of the slides in this talk was a matrix tabulating all the possible initialisation syntaxes and what they do for different kinds of types (such as: built-in types, aggregates, etc.)
Ever since then, I keep getting requests for a high-resolution version of that table. So finally I got around to uploading one. Here it is:
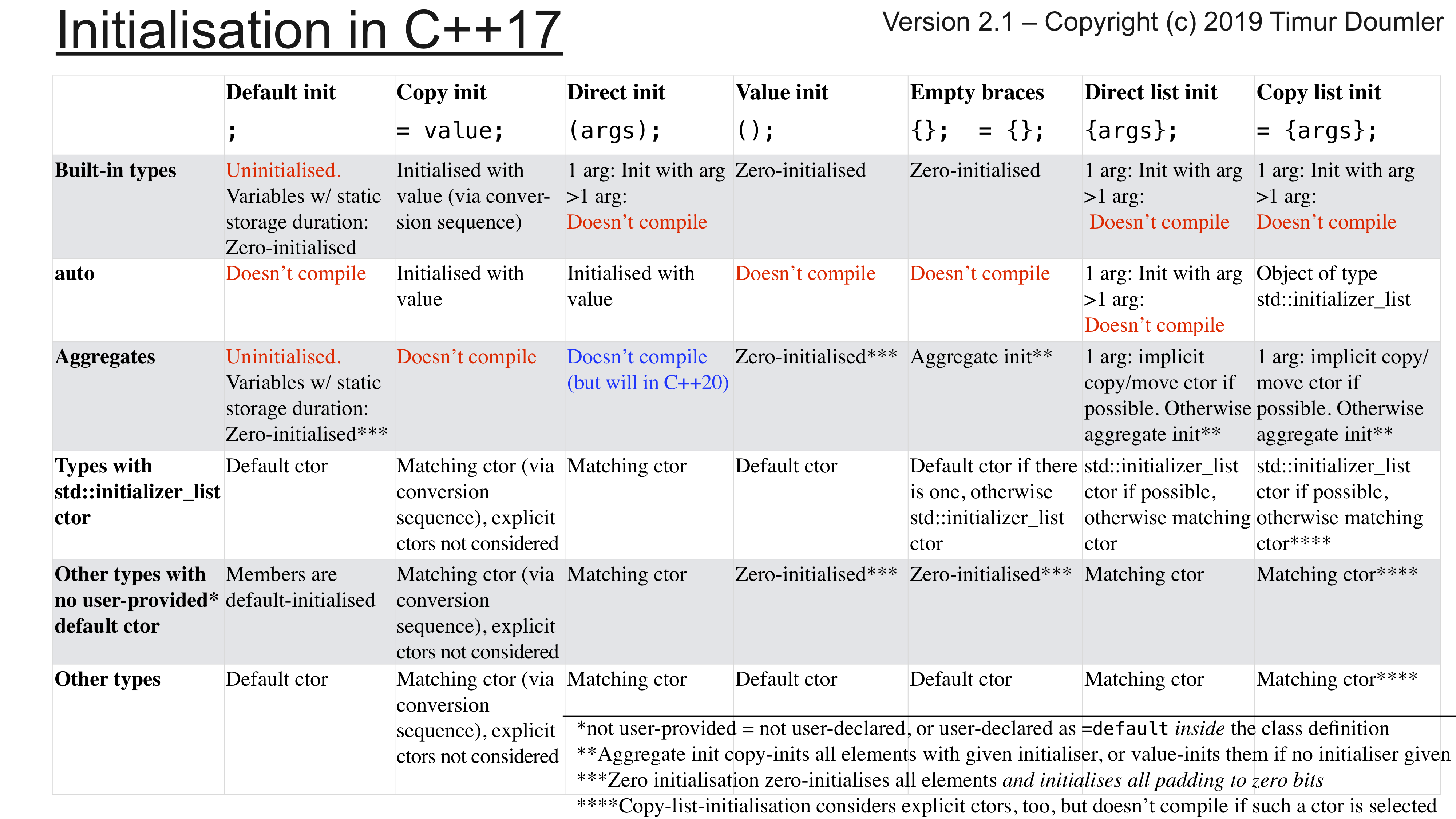
You can freely reuse this table – I hope it will be useful. And please let me know if you spot any mistakes 🙂
Keep in mind that the above table is for C++17, but things will change in C++20, in particular for aggregate types: we will get designated initialisers as well as direct initialisation for aggregates.

Trip report: February 2019 ISO C++ committee meeting, Kona, Hawai’i
What better way to start my new blog than to publish a trip report from the most recent C++ committee meeting on the wonderful Big Island of Hawai’i?
If you are looking for an incredibly detailed report of everything that happened, please instead head to this report by Bryce and others, and also see Herb Sutter’s and cor3ntin’s reports. I won’t try to provide this breadth of coverage, and instead focus on a few areas that are particularly relevant for me and the community that I am proxying here:
- Making C++ simpler, more uniform, and easier to teach;
- Providing developers with better tools;
- Improving support for low-latency and real-time(-ish) programming,
- 2D Graphics, Audio, and other forms of I/O and human-machine interaction.
That being said, let’s start with the big news: we voted both Coroutines and Modules into C++20!
Continue reading
Recent Comments